infer package t test|statistical infer : fabrication A tidier version of t.test () for two sample tests. Usage. t_test( x, formula, response = NULL, explanatory = NULL, order = NULL, alternative = "two-sided", mu = 0, conf_int = TRUE, conf_level = 0.95, . Arguments. x. A data frame that can be coerced into a tibble. formula. Hot Seat is a 2022 American action-thriller film directed and produced by James Cullen Bressack. It stars Kevin Dillon and Mel Gibson.
{plog:ftitle_list}
WEBWatch Lana Rhoades Nudes porn videos for free, here on Pornhub.com. Discover the growing collection of high quality Most Relevant XXX movies and clips. No other sex tube is more popular and features more Lana Rhoades Nudes scenes than Pornhub!
A tidier version of t.test () for two sample tests. Usage. t_test( x, formula, response = NULL, explanatory = NULL, order = NULL, alternative = "two-sided", mu = 0, conf_int = TRUE, conf_level = 0.95, . Arguments. x. A data frame that can be coerced into a tibble. formula.Needed for inference on difference in means, medians, proportions, ratios, t, .In this vignette, we’ll walk through conducting an analysis of variance .Alternatively, using the t_test wrapper: gss %>% t_test (response = hours, mu = 40) .
3. Temporary Ban. Community Impact: A serious violation of community .
Please try to provide 100% test coverage for any submitted code and always .In this vignette, we’ll walk through conducting \(t\)-tests and their randomization-based analogue using infer. We’ll start out with a 1-sample \(t\)-test, which compares a sample mean to a .
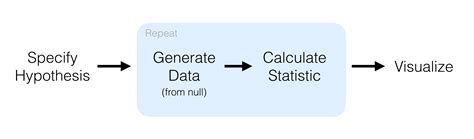
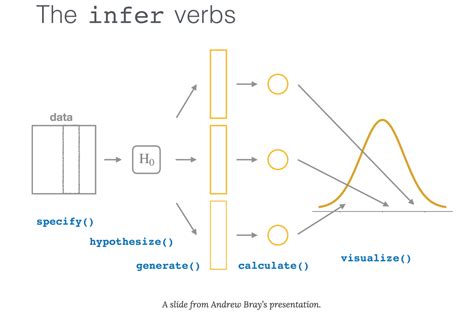
The objective of this package is to perform statistical inference using an expressive statistical grammar that coheres with the tidyverse design framework. The package is centered around 4 main verbs, supplemented with many .Rather than providing methods for specific statistical tests, this package consolidates the principles that are shared among common hypothesis tests into a set of 4 main verbs .Perform common hypothesis tests for statistical inference using flexible functions. Introduction. This article only requires the tidymodels package. The tidymodels package infer implements an expressive grammar to perform . The infer package built into tidymodels includes functions for statistical inference, which is perfect for the work I’m doing as part of my senior project. In this post, I’ll work .
tidyverse infer r
The objective of this package is to perform statistical inference using a grammar that illustrates the underlying concepts and a format that coheres with the tidyverse. For an overview of how .A tidier version of t.test() for two sample tests. Usage t_test( x, formula, response = NULL, explanatory = NULL, order = NULL, alternative = "two-sided", mu = 0, conf_int = TRUE, . A tidier version of t.test() for two sample tests. Usage t_test( x, formula, response = NULL, explanatory = NULL, order = NULL, alternative = "two-sided", mu = 0, conf_int = .
Step 1: Calculate a sample statistic, or δ. This is the main measure you care about: the difference in means, the average, the median, the proportion, the difference in proportions, the chi-squared value, etc. Step 2: Use .Learn how to perform one and two sample t-tests on vectors of data using the t.test function in R. I wanted to learn more about the doing statistical tasks in the tidyverse, so in this post I compare how the code written with the infer package compares to those available in base R. I use data sets from my book Statistics .Reproducibility. When using the infer package for research, or in other cases when exact reproducibility is a priority, be sure the set the seed for R’s random number generator. infer will respect the random seed specified in the set.seed() function, returning the same result when generate()ing data given an identical seed. For instance, we can calculate the difference in .
assume: Define a theoretical distribution calculate: Calculate summary statistics chisq_stat: Tidy chi-squared test statistic chisq_test: Tidy chi-squared test deprecated: Deprecated functions and objects fit.infer: Fit linear models to infer objects generate: Generate resamples, permutations, or simulations get_confidence_interval: Compute confidence interval
Note that the formula and non-formula interfaces (i.e. age ~ partyid vs. response = age, explanatory = partyid) work for all implemented inference procedures in infer.Use whatever is more natural for you. If you will be doing modeling using functions like lm() and glm(), though, we recommend you begin to use the formula y ~ x notation as soon as possible.
x: A data frame that can be coerced into a tibble.. formula: A formula with the response variable on the left and the explanatory on the right. Alternatively, a response and explanatory argument can be supplied.. responseA numeric value giving the hypothesized null mean value for a one sample test and the hypothesized difference for a two sample test. conf_int. A logical value for whether to include the confidence interval or not. TRUE by default. conf_level. A numeric value between 0 and 1. Default value is 0.95.. For passing in other arguments to t.test().
instron universal testing machine for sale
assume: Define a theoretical distribution calculate: Calculate summary statistics chisq_stat: Tidy chi-squared test statistic chisq_test: Tidy chi-squared test deprecated: Deprecated functions and objects fit.infer: Fit linear models to infer objects generate: Generate resamples, permutations, or simulations get_confidence_interval: Compute confidence intervalIntroduction. infer implements an expressive grammar to perform statistical inference that coheres with the tidyverse design framework. Rather than providing methods for specific statistical tests, this package consolidates the principles that are shared among common hypothesis tests into a set of 4 main verbs (functions), supplemented with many utilities to visualize and extract .infer R Package . The objective of this package is to perform statistical inference using an expressive statistical grammar that coheres with the tidyverse design framework. The package is centered around 4 main verbs, supplemented with many utilities to visualize and extract value from their outputs.
instron universal testing machine how it works
Before using a two-sample t-test, it's important to make sure of the following: . R programming language provides us with many packages to take random samples from data objects, data frames, or data tables and aggregate them into groups. . A statistical hypothesis test is a method of statistical inference used to decide whether the data at .Select set of parametric and non-parametric statistical tests. 'inferr' builds upon the solid set of statistical tests provided in 'stats' package by including additional data types as inputs, expanding and restructuring the test results. The tests included are t tests, variance tests, proportion tests, chi square tests, Levene's test, McNemar Test, Cochran's Q test and Runs test. Details. When testing with an explanatory variable with more than two levels, the order argument as used in the package is no longer well-defined. The function will thus raise a warning and ignore the value if supplied a non-NULL order argument.. The columns present in the output depend on the output of both prop.test() and broom::glance.htest().See the latter's .
Given the output of specify() and/or hypothesize() , this function will return the observed statistic specified with the stat argument. Some test statistics, such as Chisq , t , and z , require a null hypothesis. If provided the output of generate() , the function will calculate the supplied stat for each replicate.
Learn more in .We would like to show you a description here but the site won’t allow us. prop_test: Tidy proportion test; reexports: Objects exported from other packages; rep_sample_n: Perform repeated sampling; shade_confidence_interval: Add information about confidence interval; shade_p_value: Shade histogram area beyond an observed statistic; specify: Specify response and explanatory variables; t_stat: Tidy t-test statistic; t .Note that the formula and non-formula interfaces work for all implemented inference procedures in infer.Use whatever is more natural for you. If you will be doing modeling using functions like lm() and glm(), we recommend you begin to use the formula y ~ x notation as soon as possible though.. Other examples are available in the package vignettes.
We’re super excited announce the release of infer 1.0.0! infer is a package for statistical inference that implements an expressive statistical grammar that adheres to the tidyverse design framework. Rather than providing methods for specific statistical tests, this package consolidates the principles that are shared among common hypothesis tests and . The infer package works to help students understand the creation of a sampling distribution under some model, . That is, the majority of R inferential tests (e.g., t.test, chisq.test, etc.) do not play nicely with the tidyverse. To connect the the tidyverse with the central inferential ideas from introductory statistics, .
tidyverse infer package
The infer package also provides functionality to use theoretical methods for "Chisq", "F" and "t" test statistics. Generally, to find a null distribution using theory-based methods, use the same code that you would use to find the null distribution using randomization-based methods, but skip the generate() step. Where: X1 and X2 are the sample means of the two groups.; s1 and s2 are the sample variances of the two groups.; n1 and n2 are the sample sizes of the two groups.; We then need to calculate the p-value using degrees of freedom equal to (n 1 +n 2-1).If the p-value is less than your chosen significance level, we can reject the null hypothesis and say that the means .Datasets: Many R packages include built-in datasets that you can use to familiarize yourself with their functionalities. To identify built-in datasets. To identify the datasets for the infer package, visit our database of R datasets.; Vignettes: R vignettes are documents that include examples for using a package. To view the list of available vignettes for the infer package, you can visit our .A tidier version of chisq.test() for goodness of fit tests and tests of independence. Skip to content. infer 1.0.7. Get started; Reference; Articles. Tidy t-Tests with infer Tidy ANOVA (Analysis of Variance) with infer Tidy Chi-Squared Tests with infer Tidy inference for paired data Full infer Pipeline Examples. Changelog; Tidy chi-squared test .
The objective of this package is to perform statistical inference using a grammar that illustrates the underlying concepts and a format that coheres . Skip to content. infer 1.0.7. Get started; Reference; Articles. Tidy t-Tests with infer Tidy ANOVA (Analysis of Variance) with infer Tidy Chi-Squared Tests with infer Tidy inference for paired . Search the tidymodels/infer package. Vignettes. README.md Functions. 215. Source code. 41. Man pages. 24. assume: . Other wrapper functions: chisq_stat(), observe(), prop_test(), t_stat(), t_test() Examples # chi-squared test of independence for college completion # status depending on one's self-identified income class chisq_test(gss .A t test is a statistical hypothesis test that assesses sample means to draw conclusions about population means. Frequently, analysts use a t test to determine whether the population means for two groups are different. For example, it can determine whether the difference between the treatment and control group means is statistically significant
Beyond this, the infer package offers: • methods for inference using theory-based distributions • shorthand wrappers for common statistical tests using tidy data • model-fitting workflows to accommodate multiple explanatory variables. Couch et. al., (2021). infer: An R package for tidyverse-friendly statistical inference.
statistical infer
There are no messages on IC_admin's profile yet. Loading.
infer package t test|statistical infer